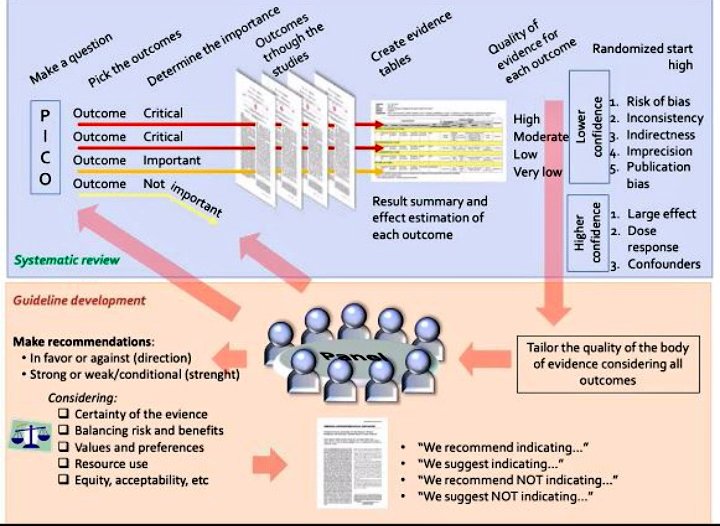
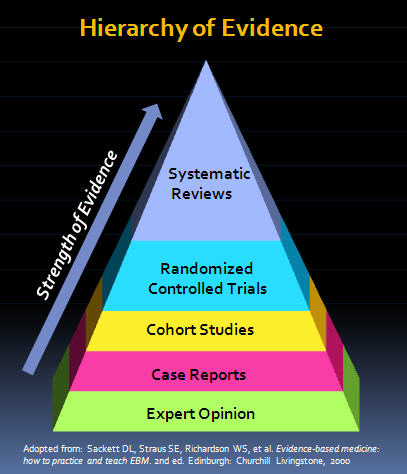
John PA Ioannidis es un médico estadounidense que trabaja en el Centro de Inovación en Meta-Investigación de Standford (METRICS) y también editor del European Journal of Clinical Investigation. Su trabajo más conocido data del año 2005, y como la mayoría no ha pasado del título aquí está al menos una sinopsis. Existe una creciente preocupación de que la mayoría de los hallazgos de investigación publicados actualmente sean falsos. La
probabilidad de que la afirmación de una investigación sea cierta puede
depender del poder y el sesgo del estudio, la cantidad de otros
estudios sobre la misma pregunta y, lo que es más importante, la
proporción de relaciones verdaderas y nulas entre las relaciones
investigadas en cada campo científico. En
este marco, es menos probable que un hallazgo de investigación sea
cierto cuando los estudios realizados en un campo son más pequeños; cuando los tamaños del efecto son más pequeños; cuando hay mayor número y menor preselección de relaciones probadas; donde hay mayor flexibilidad en los diseños, definiciones, resultados y modos analíticos; cuando hay mayor interés y prejuicio financiero y de otro tipo; y cuando más equipos están involucrados en un campo científico en busca de significación estadística. Las
simulaciones muestran que para la mayoría de los diseños y entornos de
estudio, es más probable que una afirmación de investigación sea falsa
que verdadera. Además,
para muchos campos científicos actuales, los supuestos hallazgos de la
investigación a menudo pueden ser simplemente medidas precisas del sesgo
predominante. En este ensayo, discuto las implicaciones de estos problemas para la realización e interpretación de la investigación.
Modelando el marco para hallazgos falsos positivos
Como
se mostró anteriormente, la probabilidad de que un hallazgo de
investigación sea cierto depende de la probabilidad previa de que sea
cierto, el poder estadístico del estudio y
el nivel de significancia estadística. Es
característico del campo y puede variar mucho dependiendo de si el
campo apunta a relaciones altamente probables o busca solo una o unas
pocas relaciones verdaderas entre miles y millones de hipótesis que se
pueden postular. Consideremos
también, por simplicidad computacional, campos circunscritos donde solo
hay una relación verdadera (entre muchas que se pueden hipotetizar) o
el poder es similar para encontrar cualquiera de las varias relaciones
verdaderas existentes. Y aquí el autor compara a los estudios clínicos como una prueba diagnóstica y afirma que la mayoría de los hallazgos positivos son falsos positivos.
Parcialidad
El
sesgo no debe confundirse con la variabilidad aleatoria que hace que
algunos hallazgos sean falsos por casualidad, aunque el diseño del
estudio, los datos, el análisis y la presentación sean perfectos. El sesgo puede implicar la manipulación en el análisis o el informe de los hallazgos. La información selectiva o distorsionada es una forma típica de tal sesgo.
Por
lo tanto, con el aumento del sesgo, las posibilidades de que un
hallazgo de investigación sea cierto disminuyen considerablemente. Esto se muestra para diferentes niveles de potencia y para diferentes probabilidades previas al estudio. Por el contrario, los verdaderos hallazgos de la investigación pueden ocasionalmente anularse debido al sesgo inverso. Por ejemplo, con grandes errores de medición, las relaciones se pierden en el ruido, o los investigadores usan los datos de manera ineficiente o no notan
las relaciones estadísticamente significativas, o puede haber
conflictos de intereses que tienden a “ocultar” hallazgos significativos. No
hay buena evidencia empírica a gran escala sobre la frecuencia con la
que puede ocurrir ese sesgo en diversos campos de investigación.
Sin embargo, probablemente sea justo decir que el sesgo no es tan común. Además,
los errores de medición y el uso ineficiente de los datos probablemente
se están convirtiendo en problemas menos frecuentes, ya que el error de
medición ha disminuido con los avances tecnológicos en la era molecular
y los investigadores son cada vez más sofisticados con respecto a sus
datos. El sesgo no debe confundirse con la variabilidad del azar que
puede llevar a perder una relación verdadera debido al azar.
Pruebas por varios equipos independientes
Varios equipos independientes pueden estar abordando los mismos conjuntos de preguntas de investigación. A
medida que los esfuerzos de investigación se globalizan, es
prácticamente la regla que varios equipos de investigación, a menudo
docenas de ellos, puedan investigar las mismas preguntas o similares. Desafortunadamente,
en algunas áreas, la mentalidad predominante hasta ahora ha sido la de
centrarse en descubrimientos aislados por equipos individuales e
interpretar los experimentos de investigación de forma aislada. Un
número cada vez mayor de preguntas tienen al menos un estudio que
reclama un hallazgo de investigación, y esto recibe atención unilateral.
Corolarios
Apela a la visión sistémica y de conjunto del fenómeno.
Corolario
1: Cuanto más pequeños son los estudios realizados en un campo
científico, menos probable es que los hallazgos de la investigación sean
ciertos
Corolario
2: Cuanto más pequeños son los tamaños del efecto en un campo
científico, menos probable es que los hallazgos de la investigación sean
ciertos
Corolario
3: cuanto mayor sea el número y menor la selección de relaciones
probadas en un campo científico, es menos probable que los hallazgos de
la investigación sean ciertos.
Corolario
4: cuanto mayor sea la flexibilidad en los diseños, las definiciones,
los resultados y los modos analíticos en un campo científico, es menos
probable que los hallazgos de la investigación sean ciertos.
La
flexibilidad aumenta el potencial para transformar lo que serían
resultados “negativos” en resultados “positivos”, es decir, sesgo . Para varios diseños de investigación, por ejemplo, ensayos controlados aleatorios o metanálisis, se han realizado esfuerzos para estandarizar su conducta y presentación de informes. Es probable que la adherencia a los estándares comunes aumente la proporción de hallazgos verdaderos. Lo mismo se aplica a los resultados. Los
hallazgos verdaderos pueden ser más comunes cuando los resultados son
inequívocos y universalmente aceptados (p. ej., la muerte) en lugar de
cuando se diseñan resultados múltiples (p. ej., escalas para los
resultados de la esquizofrenia). De
manera similar, los campos que utilizan métodos analíticos
estereotipados comúnmente acordados (por ejemplo, diagramas de
Kaplan-Meier y la prueba de rango logarítmico) puede generar una mayor proporción de hallazgos verdaderos que los
campos donde los métodos analíticos aún están bajo experimentación (p.
ej., métodos de inteligencia artificial) y solo se informan los
"mejores" resultados.
De todos modos, incluso en los diseños de investigación más estrictos, el sesgo parece ser un problema importante. Por
ejemplo, hay pruebas sólidas de que la notificación selectiva de los
resultados, con la manipulación de los resultados y los análisis
notificados, es un problema común incluso en los ensayos aleatorios. La simple abolición de la publicación selectiva no resolvería este problema.
Corolario
5: Cuanto mayores son los intereses y prejuicios financieros y de otro
tipo en un campo científico, menos probable es que los hallazgos de la
investigación sean ciertos. Los conflictos de interés y los prejuicios pueden aumentar el sesgo. Los conflictos de intereses son muy comunes en la investigación biomédica y, por lo general, se informan de manera inadecuada y escasa. El prejuicio puede no tener necesariamente raíces financieras. Los
científicos en un campo determinado pueden tener prejuicios simplemente
por su creencia en una teoría científica o por su compromiso con sus
propios hallazgos. Muchos
estudios universitarios aparentemente independientes pueden llevarse a
cabo sin otra razón que la de otorgar a los médicos e investigadores
calificaciones para la promoción o la permanencia en el cargo. Dichos conflictos no financieros también pueden dar lugar a resultados e interpretaciones distorsionados. Investigadores
de prestigio pueden suprimir el proceso de revisión por pares
la aparición y la difusión de hallazgos que refuten sus hallazgos,
condenando así a su campo a perpetuar falsos dogmas. La evidencia empírica sobre la opinión de expertos muestra que es extremadamente poco fiable.
Corolario
6: Cuanto más candente es un campo científico (con más equipos
científicos involucrados), menos probable es que los hallazgos de la
investigación sean ciertos. Este
corolario aparentemente paradójico se debe a que, como se indicó
anteriormente, el valor predictivo positivo de los hallazgos aislados disminuye cuando muchos
equipos de investigadores están involucrados en el mismo campo. Esto
puede explicar por qué ocasionalmente vemos una gran emoción seguida
rápidamente por severas decepciones en campos que llaman mucho la
atención. Con muchos
equipos trabajando en el mismo campo y con la producción de datos
experimentales masivos, el tiempo es esencial para vencer a la
competencia. Así, cada equipo puede priorizar la búsqueda y difusión de sus resultados “positivos” más impresionantes. Los
resultados "negativos" pueden volverse atractivos para la difusión solo
si algún otro equipo ha encontrado una asociación "positiva" en la
misma pregunta. En ese caso, puede resultar atractivo refutar una afirmación realizada en alguna revista de prestigio. La evidencia empírica sugiere que esta secuencia de extremos opuestos es muy común en la genética molecular.
Estos corolarios consideran cada factor por separado, pero estos factores a menudo se influyen entre sí. Por
ejemplo, es más probable que los investigadores que trabajan en campos
en los que se percibe que el tamaño del efecto real es pequeño realicen
estudios grandes que los investigadores que trabajan en campos en los
que se percibe que el tamaño del efecto real es grande. O
el prejuicio puede prevalecer en un campo científico candente,
socavando aún más el valor predictivo de los hallazgos de su
investigación. Las partes
interesadas con muchos prejuicios pueden incluso crear una barrera que
aborte los esfuerzos para obtener y difundir resultados opuestos. Por
el contrario, el hecho de que un campo esté de moda o tenga fuertes
intereses invertidos a veces puede promover estudios más amplios y
mejores estándares de investigación, mejorando el valor predictivo de
los resultados de su investigación.

En el marco descrito, un PPV superior al 50% es bastante difícil de conseguir. Un hallazgo de un ensayo
controlado aleatorizado bien realizado y con un poder estadístico
adecuado que comienza con una probabilidad previa al estudio del 50 % de
que la intervención es efectiva es finalmente cierto en aproximadamente
el 85 % de las veces. Se
espera un desempeño bastante similar de un metanálisis confirmatorio de
ensayos aleatorizados de buena calidad: el sesgo potencial probablemente
aumenta, pero el poder estadístico y las posibilidades previas a la
prueba son mayores en comparación con un único ensayo aleatorizado. Los
hallazgos de la investigación de los ensayos clínicos de fase temprana
con poca potencia serían ciertos aproximadamente una de cada cuatro
veces, o incluso con menos frecuencia si hay sesgo. Los
estudios epidemiológicos de naturaleza exploratoria funcionan incluso
peor, especialmente cuando no tienen suficiente potencia, pero incluso
los estudios epidemiológicos con buena potencia pueden tener solo una
posibilidad entre cinco de ser ciertos. Finalmente,
en la investigación orientada al descubrimiento con pruebas masivas,
donde las relaciones probadas superan las verdaderas 1000 veces (p. ej.,
30 000 genes probados, de los cuales 30 pueden ser los verdaderos
culpables), el VPP para cada relación declarada es extremadamente bajo , incluso
con una estandarización considerable de los métodos estadísticos y de
laboratorio, los resultados y la notificación de los mismos para
minimizar el sesgo.
Los hallazgos de investigación afirmados a menudo pueden ser simplemente medidas precisas del sesgo predominante
Como
se muestra, la mayoría de la investigación biomédica moderna está
operando en áreas con muy baja probabilidad antes y después del estudio
de obtener hallazgos verdaderos. Supongamos que en un campo de investigación no hay hallazgos verdaderos por descubrir. La
historia de la ciencia nos enseña que, en el pasado, el esfuerzo
científico a menudo ha desperdiciado esfuerzos en campos sin ningún
rendimiento de información científica verdadera, al menos según nuestra
comprensión actual. En tal
"campo nulo", idealmente se esperaría que todos los tamaños del efecto
observados varíen por casualidad alrededor del nulo en ausencia de
sesgo. La medida en que
los hallazgos observados se desvían de lo esperado por pura casualidad
sería simplemente una medida pura del sesgo predominante.
Por
ejemplo, supongamos que ningún nutriente o patrón dietético son
realmente determinantes importantes para el riesgo de desarrollar un
tumor específico. Supongamos
también que la literatura científica ha examinado 60 nutrientes y
afirma que todos ellos están relacionados con el riesgo de desarrollar
este tumor con riesgos relativos en el rango de 1,2 a 1,4 para la
comparación de los tercilos de ingesta superior e inferior. Entonces,
los tamaños del efecto declarados simplemente miden nada más que el
sesgo neto que ha estado involucrado en la generación de esta literatura
científica. Los tamaños del efecto declarados son, de hecho, las estimaciones más precisas del sesgo neto. Incluso
se deduce que entre los "campos nulos", los campos que reclaman efectos
más fuertes (a menudo acompañados de afirmaciones de importancia médica
o de salud pública) son simplemente aquellos que han sufrido los peores
sesgos.
Para campos con VPP muy bajo, las pocas relaciones verdaderas no distorsionarían mucho esta imagen general. Incluso
si algunas relaciones son verdaderas, la forma de la distribución de
los efectos observados aún brindaría una medida clara de los sesgos
involucrados en el campo. Este concepto invierte totalmente la forma en que vemos los resultados científicos. Tradicionalmente,
los investigadores han visto con entusiasmo los efectos grandes y muy
significativos, como signos de importantes descubrimientos. En
realidad, es más probable que los efectos demasiado grandes y demasiado
significativos sean signos de un gran sesgo en la mayoría de los campos
de la investigación moderna. Deben
conducir a los investigadores a un pensamiento crítico cuidadoso sobre
lo que podría haber salido mal con sus datos, análisis y resultados. efecto de inmersión en la cultura no puede ver el agua como el pez.
Por
supuesto, es probable que los investigadores que trabajan en cualquier
campo se resistan a aceptar que todo el campo en el que han desarrollado
sus carreras es un "campo nulo". Sin
embargo, otras líneas de evidencia, o avances en tecnología y
experimentación, pueden conducir eventualmente al desmantelamiento de un
campo científico. La
obtención de medidas del sesgo neto en un campo también puede ser útil
para obtener una idea de cuál podría ser el rango de sesgo que opera en
otros campos donde pueden estar operando métodos analíticos, tecnologías
y conflictos similares.
¿Cómo podemos mejorar la situación?
¿Es inevitable que la mayoría de los hallazgos de la investigación sean falsos o podemos mejorar la situación? Un problema importante es que es imposible saber con 100% de certeza cuál es la verdad en cualquier pregunta de investigación. En este sentido, el estándar de "oro" puro es inalcanzable. Sin embargo, existen varios enfoques para mejorar la probabilidad posterior al estudio.
La
evidencia con mejor poder estadístico, por ejemplo, estudios grandes o
metanálisis de bajo sesgo, puede ayudar, ya que se acerca al estándar
"oro" desconocido. Sin embargo, los estudios grandes aún pueden tener sesgos y estos deben reconocerse y evitarse. Además,
es imposible obtener evidencia a gran escala para todos los millones y
trillones de preguntas de investigación planteadas en la investigación
actual. La evidencia a
gran escala debe orientarse a las preguntas de investigación en las que
la probabilidad previa al estudio ya es considerablemente alta, de modo
que un hallazgo de investigación significativo conduzca a una
probabilidad posterior a la prueba que se consideraría bastante
definitiva. La evidencia a
gran escala también está particularmente indicada cuando puede probar
conceptos importantes en lugar de preguntas estrechas y específicas. Un
resultado negativo puede entonces refutar no solo una afirmación
propuesta específica, sino todo un campo o una parte considerable del
mismo. Seleccionar el
rendimiento de estudios a gran escala con base en criterios estrechos de
miras, como la promoción comercial de un fármaco específico, es en gran
medida una investigación desperdiciada. Además,
se debe tener cuidado de que los estudios extremadamente grandes tengan
más probabilidades de encontrar una diferencia significativa desde el
punto de vista estadístico formal para un efecto trivial que en realidad
no es significativamente diferente del efecto nulo.
En
segundo lugar, muchos equipos abordan la mayoría de las preguntas de
investigación, y es engañoso enfatizar los hallazgos estadísticamente
significativos de un solo equipo. Lo que importa es la totalidad de la evidencia. También puede ayudar la disminución del sesgo a través de mejores estándares de investigación y la reducción de los prejuicios. Sin embargo, esto puede requerir un cambio en la mentalidad científica que puede ser difícil de lograr. En
algunos diseños de investigación, los esfuerzos también pueden tener
más éxito con el registro inicial de estudios, por ejemplo, ensayos
aleatorios. El registro supondría un desafío para la investigación generadora de hipótesis. Algún
tipo de registro o conexión en red de recopilaciones de datos o
investigadores dentro de los campos puede ser más factible que el
registro de todos y cada uno de los experimentos generadores de
hipótesis. Independientemente,
incluso si no vemos un gran progreso con el registro de estudios en
otros campos, los principios de desarrollar y adherirse a un protocolo
podrían tomarse más ampliamente de los ensayos controlados aleatorios.
Finalmente, en lugar de perseguir la significación estadística, debemos mejorar nuestra comprensión del rango de valores de probabilidades previas al estudio, donde operan los esfuerzos de investigación. Antes
de realizar un experimento, los investigadores deben considerar cuáles
creen que son las posibilidades de que estén probando una relación
verdadera en lugar de una relación no verdadera. Como
se describió anteriormente, siempre que sea éticamente aceptable, se
deben realizar estudios grandes con un sesgo mínimo sobre los resultados
de la investigación que se consideren relativamente establecidos, para
ver con qué frecuencia se confirman. Sospecho que varios "clásicos" establecidos fallarán la prueba.
Sin
embargo, la mayoría de los nuevos descubrimientos seguirán surgiendo de
investigaciones generadoras de hipótesis con probabilidades previas al
estudio bajas o muy bajas. Entonces
deberíamos reconocer que las pruebas de significación estadística en el
informe de un solo estudio dan solo una imagen parcial, sin saber
cuántas pruebas se han realizado fuera del informe y en el campo
relevante en general. A pesar de una gran literatura estadística para múltiples correcciones de prueba,
por lo general es imposible descifrar cuántos datos extraídos por los
autores informantes u otros equipos de investigación han precedido a un
hallazgo de investigación informado. Incluso si determinar esto fuera factible, esto no nos informaría sobre las probabilidades previas al estudio. Por
lo tanto, es inevitable que uno deba hacer suposiciones aproximadas
sobre cuántas relaciones se espera que sean verdaderas entre aquellas
investigadas en los campos de investigación y diseños de investigación
relevantes. El campo más amplio puede brindar alguna orientación para estimar esta probabilidad para el proyecto de investigación aislado. También sería útil aprovechar las experiencias de los sesgos detectados en otros campos vecinos. Aunque estas suposiciones serían considerablemente subjetivas, serían muy útiles para interpretar las afirmaciones de la investigación y ponerlas en contexto.
Pintura: Georg Scholz. Pintor alemán.