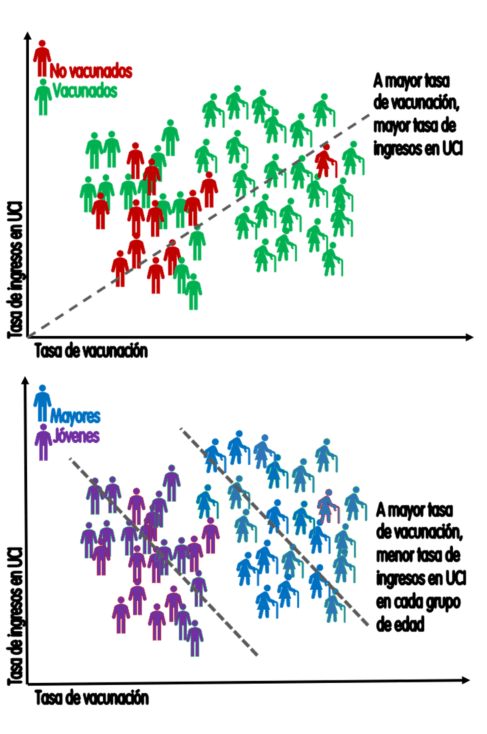
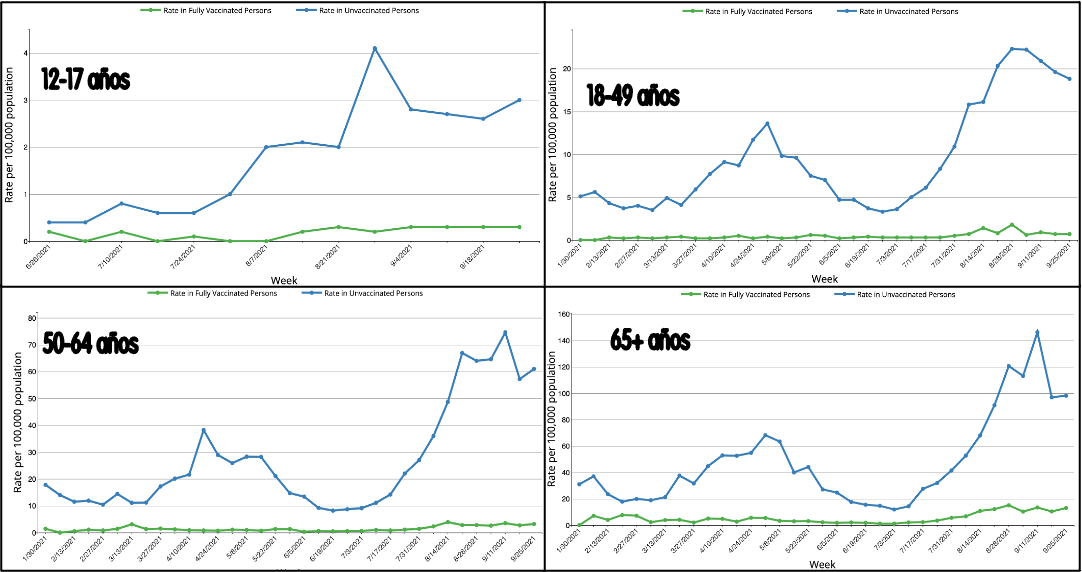
1. Establecer que se va a medir como medida de efectividad: la medida que se ha utilizado a partir de la difusión en la prensa, fue la de la eficacia que mostró en sus ensayos clínicos iniciales para disminuir la infección. Pero la comparación también debe realizarse para otros efectos, tales como la eficacia para prevenir la internación en UCI o la mortalidad.
2. Determinar cuando: esto es relevante por dos razones, la primera es porque ya sabemos que algunos efectos (como prevenir la infección) se pueden perder luego de algunos meses por la disminución de los anticuerpos neutralizantes. Por ello en varios estudios se suele reportar la eficacia cuando la última dosis fue dada más alla de 5 meses o durante los últimos 5 meses. La otra razón es que cada variante del virus ha mostrado un escape inmunológico distinto, por lo que no es lo mismo comparar el invierno de 2021 (donde la variante gama fue predominante) con el verano 2022, donde ha predominado la variante ómicron. Al menos esto es cierto para Argentina.
3. Dónde se va a medir: sin duda la eficacia de las vacunas no es igual según las edades, o la competencia inmunológica de quienes las reciben. Cuando comparamos poblaciones no resulta distinto. No es lo mismo comparar Estados Unidos (con mucha población con comorbilidades como la obesidad y la hipertensión) con la mayoría de los países europeos. Y aun en países europeos, debe tenerse en cuenta que están altamente "envejecidos", que así se los llama cuando la población mayor de 65 años supera el 20% de la población general. En Argentina una pirámide poblacional envejecida es posible ver en la Ciudad de Buenos Aires. Por ello, a fines de comparar la eficacia, resulta más atractivo encontrar estudios donde distintas vacunas hayan sido aplicadas a una misma población. Aunque esto ha sucedido en muchos países no todos los países han publicado sus experiencias.
3. Con qué parametros: este es un tema estadístico, pero no porque sea técnico deja de ser menor. Un estudio en Hungría fue presentado por el Instituto Gamaleya como prueba de la superioridad de Sputnik V frente a Pfizer. La vacuna Sputnik V redujo en un 85.7% las infecciones frente al 83.3% de Pfizer. Sin duda, aunque la diferencia sea de apenas un 2.4%, un número es mayor que otro. ¿Pero así se mide la efectividad en los estudios? La respuesta es NO.

En el caso de Sputnik V el intervalo de confianza del 95% , para prevenir la infección, varia entre el 84.4% y el 86.9% . O sea que la eficacia real osciló entre esos dos valores en el 95% de las veces. Al menos para ese momento, para ese lugar y para el efecto que se está midiendo. Un valor de 85% también sería cierto, y otro valor del 86% también. Pero un valor tan alto como el 87% o tan bajo como el 83%, ambos por fuera del intervalo de confianza, solo aparecen en menos del 5% de los casos.
En el caso de Pfizer el intervalo de confianza oscila entre el 82.6% y el 83.9%. Y cuando queremos comparar con otros tratamientos (en este caso vacunas), diremos que son diferentes si el intervalo de confianza de una no se superpone con el otro intervalo. Esto es la forma en que se deben leer, y no otra.
Veamos un estudio que cumple con algunas de las características que pretendemos:
A mitad del año 2021, comenzaron a aparecer los estudios de la "vida real", o estudios de efectividad. Un estudio relevante es el de Hungria, publicado en Nature, observó lo sucedido entre enero y junio de 2021 a 3.740.066 personas que recibieron dos dosis de vacunas de Pfizer, Sputnik-V, AstraZeneca, Sinopharm o Moderna. Aunque durante esos meses en Hungría la variante dominante era la alfa, nos sirve de ejemplo para comparar la efectividad de distintas vacunas en la vida real.
La efectividad ajustada contra la infección varió entre el 68,7% y el 88,7.
La efectividad para prevenir la mortalidad varió entre el 87,8% y el 97,5%. Con una
efectividad del 100% en personas de 16 a 44 años para todas las vacunas. Lo que esto último quiere decir que para ese período no hubo muertes entre los vacunados en ese grupo de edad.
Después del ajuste por edad, sexo y día calendario, la efectividad estimada contra la infección por SARS-CoV-2 , para cada una de las vacunas administradas, fue la siguiente:
Pfizer-BioNTech: 83,3% (IC del 95%: 82,6–83,9%);
Moderna: 88,7% (IC del 95%: 86,6–90,4%);
Sputnik-V 85,7% (IC del 95%: 84,3-86,9%);
AstraZeneca: 71,5% (IC del 95%: 69,2–73,6%);
Sinopharm: 68,7% (IC 95% 67,2-70,1%)
Mientras que la efectividad para disminuir la mortalidad reportó esto:
Pfizer-BionTech: 90.6% (IC del 95%: 89.4-91.5%);
Moderna: 93.6% (IC del 95%: 90.5-95.7%);
Sputnik- V: 97.5% (IC del 95%: 95.6-98.6%);
AstraZeneca: 88.3% (IC del 95%: 78.7-93.5%)
Sinopharm: 87.8% (IC del 95%: 86.1-89.4%)
Seguramente volvió a mirar el primer número que es el promedio, pero ya habíamos dicho que lo que importa es el rango (o sea el intervalo de confianza). Prestando atención al intervalo de confianza se puede decir que la efectividad para disminuir la infección fue igual para Moderna y Sputnik-V, y apenas menor para Pfizer, y luego las vacunas de AstraZeneca y Sinopharm, sin diferencias entre ellas.
Recordemos que el estudio fue terminado en Junio de 2021, en ese entonces todavía no era relevante la disminución de los anticuerpos y las vacunas parecian funcionar igual para la variante alfa. Algo que cambiaría con delta y más aun con ómicron, por lo que estos datos son ciertos, pero solo para esa variante alfa y para el tiempo que fue estudiado. Pero fueron relevantes para demostrar que aunque Sputnik-V era apenas mejor que Pfizer, su efectividad era tan buena como la vacuna de Moderna. Pero también es relevante para decir que el desempeño de las vacunas, todas las vacunas utilizadas, era muy alto. Frente a la evasión inmune que hay para disminuir las infecciones frente a la variante ómicron todos estos datos ciertamente han perdido vigencia.
Pero analizando los datos de efectividad para la mortalidad esa diferencia se diluye y al menos 4 vacunas (Sinopharm, Pfizer, Moderna y AstraZeneca) que prácticamente solapan sus intervalos de confianza, por lo que puede decirse que son iguales, y Sputnik-V vuelve a sobresalir y solo solapa su rango de efectividad la vacuna de Moderna.

Cuando uno lee estos datos o cualquiera siempre es relevante la forma en que son "enmarcados". Uno puede resaltar que la vacuna Sputnik-V es la más efectiva (como presentó el Instituto Gamaleya a este estudio), pero también puede decir que fue tan buena como la vacuna de Moderna, o también decir que las vacunas ARNm no parecen brindar mayor ventaja que las tradicionales.
Pero estos números esconden otras cosas: como que en Hungría,
las vacunas de Pfizer y Moderna fueron las opciones preferidas
para los pacientes con enfermedades crónicas como diabetes tipo 2 o
enfermedades cardiovasculares, que pueden disminuir la eficacia de la
vacuna.
Este es uno de
los primeros estudios que examinar la efectividad individual de la
vacuna Moderna en un entorno del mundo real entre 222,892 personas, de
las cuales el 36% tenía 65 años o más. La efectividad general fue del
88,7% contra la infección por SARS-CoV-2 y del 93,6% contra la muerte
relacionada con Covid-19 al menos una semana después de la segunda dosis. Los
resultados confirman la altísima eficacia de la vacuna de ARNm de
Moderna en ensayos clínicos y en entornos del mundo real.
Resalta también la alta efectividad de la vacuna Sinopharm, de la cual se tienen escasos o nulos reportes en otros países. Aunque Machia y Ferrante encontraron en nuestro medio, en ocasión de valorar vacunas alternativas en lugar de la segunda dosis de Sputnik-V en Argentina, que la vacuna de Sinopharm lograba menos antigenicidad que otras que estaban disponibles (AstraZeneca, 2da dosis de Sputnik-V y Moderna). También son escasos los de otra vacuna China (SinoVac) cuyo análisis de efictividad fue más que relevante en un estudio sobre 10 millones de personas en Chile (Jara et al).
Aun cuando el estudio reune a vacunados y no vacunados en un mismo país y con una misma variante puede tener limitaciones importantes. En primer lugar, el
período de estudio fue diferente para cada vacuna, por lo que el
análisis asume implícitamente que el efecto de cada covariable, incluida
la vacunación, es constante durante el seguimiento. En segundo lugar, a
pesar de los ajustes por edad, sexo y día calendario, no se incluyeron
otras covariables importantes como las comorbilidades, los medicamentos o
el estado socioeconómico.
Unos meses después de finalizado el estudio, en noviembre de 2021, Hungría tuvo una ola con la variante delta y en febrero de 2022 otra mayor con la variante ómicron.. Por datos de otros países sabemos que esto erosionó en mucho la efectividad de las vacunas para disminuir la infección.
En febrero de 2022 otro estudio fue publicado sobre Hungría (variantes alfa y delta), donde los autores señalan que la disminución de la efectividad comenzó a caer para todas las vacunas, en especial para AstraZeneca, Sinopharm y Sputnik-V. Por lo que a partir de mediados de agosto de 2021 comenzó a aplicarse una dosis adicional pero solo con vacunas ARNm.

Este último estudio es interesante porque afirma que se recuperó la efectividad para la infección, pero no aportó los números discriminados para cada uno de los efectos con sus respectivos intervalos de confianza. Por los gráficos es posible observar que los intervalos de confianza prácticamente todos se superponen, por lo que pudieran valer las mismas consideraciones que antes. Salvo que esta vez se trata de esquemas de vacunación mixtos o heterólogos.
Argentina también utiliza varias vacunas, aunque recién en 2022 ha agregado masivamente las vacunas ARNm. Las preferencias por marcas son comunes entre los medicamentos habituales en las prescripciones médicas, aunque en Argentina desde el 2002 se puede prescribir por el nombre genérico. Probablemente por que las vacunas son mayoritariamente provistas por el estado ni los propios médicos conocemos, en general, cual es el fabricante para el resto de las vacunas que se están dando en el país. Seguramente la situación de crisis por el virus y la exposición mediática, aunque no se debe descartar bastante de guerra comercial ha influido en el ánimo de los médicos y la gente en las preferencias por una u otra vacuna. En toda América Latina se instaló entre muchos que "Pfizer es la mejor vacuna", algo que no pudo ser comprobado en este estudio, como tampoco se puede comprobar que Sputnik-V lo sea. Lo que no se debe olvidar es que ambos han tenido problemas de provisión de sus vacunas en la primera mitad del 2021, lo que dió lugar a que muchos países usaran esquemas heterólogos.
Hoy países como Argentina han comenzado a aplicar sus dosis adicionales y de refuerzo con vacunas ARNm, por lo que esta información sería solo relevante para aquellos que aun no hubieran recibido el esquema primario, claro está siempre que pudieran ser capaces de elegir, algo que ha sucedido en varios lugares pero por decisión de autoridades locales.
Más estudios serían necesarios para ver que ha sucedido durante la última ola con la variante ómicron. Aunque estudios de otros países ya nos adelantan que la efectividad para disminuir la infección cayó para todas las vacunas pero se preserva todavía una alta efectividad para disminuir los casos graves y la mortalidad. Pero en este último efecto la diferencia entre las vacunas no parece mostrar diferencias marcadas ni entre tecnologías usadas ni entre fabricante.
El monitoreo que muchos países hacen sobre la efectividad en el mundo real sigue siendo necesario para establecer los tiempos de refuerzo, donde la permanencia de la inmunidad en el tiempo será otra de las variables a destacar a la hora de comparar la perfomance de las diferentes vacunas.